
Enterprise Co-Pilot on AWS - Buy Amazon Q For Business or Build Your Own?
Generative AI and LLMs(large language models) are very popular now. Virtually every business nowadays has either a plan for AI adoption or adopted it in some way. Being able to further automate boring and time-consuming processes using natural human language attracts a lot of minds.
In this blog post I want to explore ways to launch PoCs(Proof of Concepts) inside the organization to identify whether further adoption of GenAI/LLMs can be beneficial for the business. This is not a scientific article, nor we are discussing design and training of our own models. This is about checking whether using something that’s already on the market can be used. Our goal is to have something usable in the end so we can actually interact with it.
The Problem
I would like to use our company as an example. We are for a while in the business of custom software development and digital transformation. Some things (like processes and best-practices) are documented and stored in our knowledge base. Other stuff can be a part of tribal knowledge and also be mentioned/described/stored in emails, slack messages, or some documents.
When we hire an external contractor, e.g. marketing or sales, it requires some time for me to onboard them, explain company policies, culture, and values. Some time is also needed to get familiar with the rest of the team. Furthermore, there may be task-specific questions about the company. Since we already have a large knowledge base, combining it with some transactional data (like emails, messages) could allow us to create a corporate knowledge base, and personal assistant (co-pilot) with a deep knowledge of AgileVision for everyone on the team.
Limitations
We care a lot about data security and privacy. This also affects tools we can allow ourselves to use. There are many AI-based tools on the market, but besides the efficient underlying models, we also need to be sure our data won’t be used for model training purposes and will never leave our cloud infrastructure.
This leads us to the choice of the platform for our AI experiments. We deal a lot with AWS and their AI infrastructure is pretty impressive. Amazon Web Services is transparent about the way your data is going or not going to be used and gives the required amount of control over our data.
Apart from privacy benefits, implementing AI initiatives in our cloud account, we benefit from simplified operations, including using Infrastructure as a Code to allocate required resources, centralized billing with a powerful cost analysis tools.
Build or buy?
Building something from scratch or buying a ready-to-use solution is a dillemma of every organization leader. Before making any decision, we decide on the priorities. Our goal is to launch PoC as soon as possible, and explore limitations we may face as soon as it’s possible. This gives us an easy answer for the eternal dilemma - we are going to “buy”(in a very smart way) the solution first, and decide whether we want to build later.
Isn’t buying something and then building your own tool a waste of money? It could become a waste of money, if we are actually buying it. Instead, we’ll be acting fast, smart, and lean. Amazon Q Business offers a generous trial for 60 days, which allows us to deploy our proof of concept fast and with the minimum spend on the underlying infrastructure. Now that’s what I call the agile approach!
Amazon Q Business - Managed Artificial Intelligence Solution for Enterprise
Amazon Q For Business is a managed service which provides an AI-based assistant capable of answering questions, generating content, and perform various tasks by using the data from various corporate data sources.
The idea is that you can connect your important data sources, like knowledge bases, email accounts, support systems, websites, and file storage and use those for training of your AI agents. Imagine, the data siloed before in various systems now can be connected in a central knowledge base accessible with a help of conversational Artificial Intelligence agent.
As of know, the following data sources can be connected:
- Email: Google Email, Microsoft Exchange
- File storage: Microsoft One Drive / Google Drive / Dropbox/ Box.com / Amazon S3 / Microsoft SMB
- Communication/Collaboration: Microsoft Teams / Quip / Microsoft Yammer
- Documents: Microsoft Sharepoint / Amazon Workdocs / Atlassian Confluence
- Bug trackers/task trackers/support: Atlassian Jira, Zendesk
- Development: GitHub
- Databases: Microsoft SQL Server/IBM DB2 / PostgreSQL / Amazon RDS / Aurora
- Websites/CMS: website crawler / Drupal / Adobe Experience Manager / Alfresco
- Custom data source
A full list is available of connectors can be found on the official documentation page for Amazon Q Business.
Real world Amazon Q Business Example
From the previous section, it seems like connecting all the data sources and creating an AI agent gives your organization an immediate boost in productivity by having an omnipotent AI(yes, that was a Startrek reference) aware about every aspect of your business which can enable team members to be more efficient at their jobs. Let’s check if that’s the case.
Step 1 - Creating Amazon Q Business Application
First, we need to create our Amazon Q Business application. We can go with suggested defaults for our proof of concept:
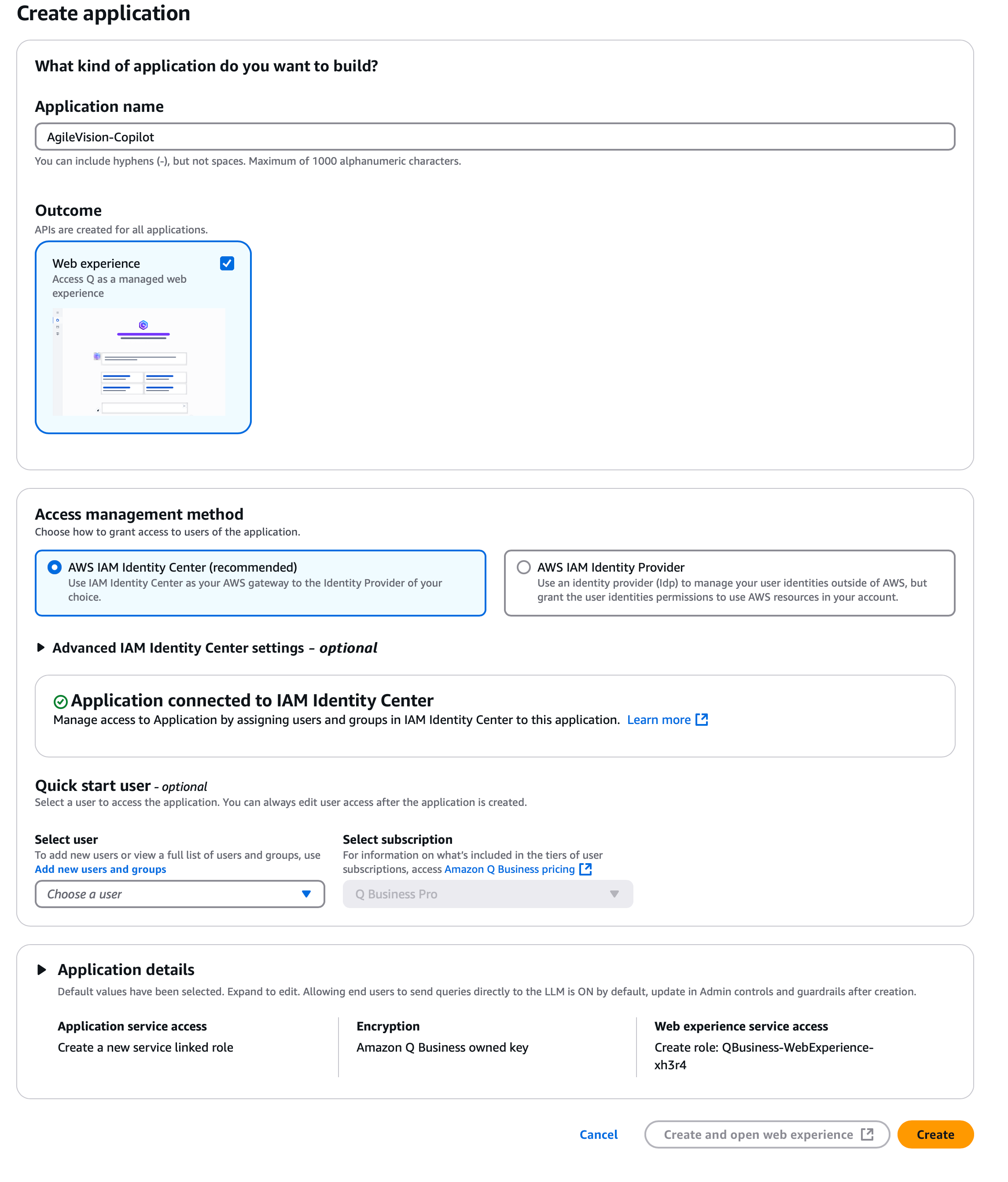
After providing the required information, go ahead the click the “Create” button. It will take some time for AWS to create Amazon Q Business application. Once ready, proceed to the next step
Step 2 - Configure data sources
Once the application is created, we need to start adding data sources. For our proof of concept, we are going to add the following corporate data sources:
- Emails - we are using Google Workspace mail
- Confluence - since it’s our main knowledge base
- Website - to ensure our AI agents are on the same page with the marketing department
Connectors configuration is somewhat cumbersome, case-specific and won’t be covered in this blog post. You can follow the official connector documentation. Once properly configured, indexing process will start. Depending on the data volume, it can take a while.
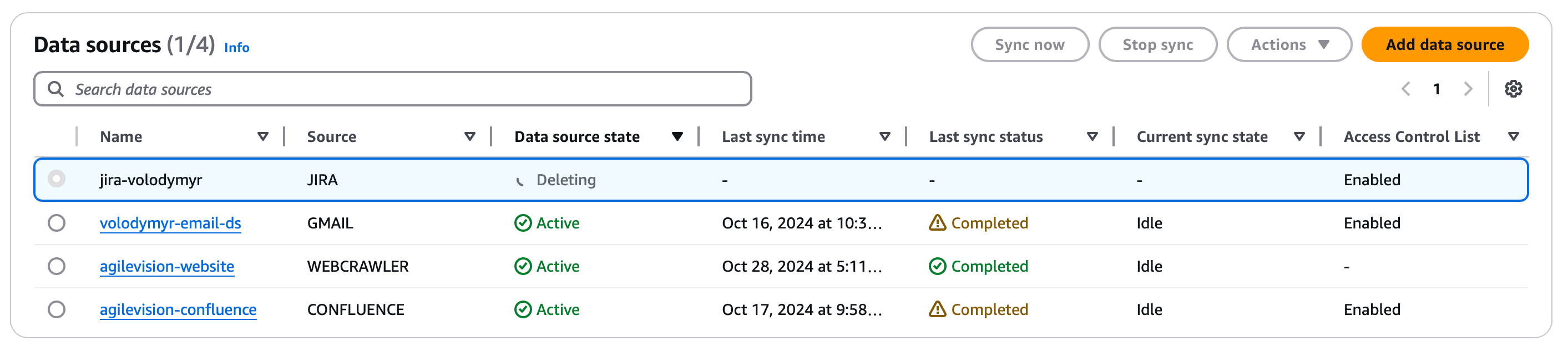
One important thing to consider, is that the amount of data your Amazon Q Business application can process and store for RAG(Retrieval-augmented generation) needs is determined by the retriever configuration. Enterprise retriever has multi availability zone deployment scheme for availability purposes and can support up to 1 000 000 documents in the index.
Each provisioned index of the retriever supports up to 20 000 documents or 200 megabytes of data in total. A document is a single unit of information in the source system. Feel free to check the official documentation in order to figure out what’s considered a document depending on the system.
Some of data sources can contain a large number of small documents. Consider email for example, where each message is a document and each attachment is a seaprate document also. In the case of Gmail, Amazon Q Business connector by default will be fetching all emails from all accounts in the provided Google Workspace. Without a proper filtering, it’s very easy to hit the limit of 20000 documents, especially if users are getting a large number of transactional emails.
Step 3 - Configure guardrails
To ensure our AI assistant follows organization policies and guidelines, we may want to configure additional guardrails for the application. It’s possible to reduce the risk of hallucinations to ensure Amazon Q only uses data from underlying data sources without falling back to a “generic” knowledge of LLM. Depending on your preference, you can still leave the option to use LLM itself for answers or completely disable it.
It’s also possible to augment or completely block some topic. Let’s assume, for example, we need to ensure no mention of a certain topic is present from LLM answers. I will use myself as an example:
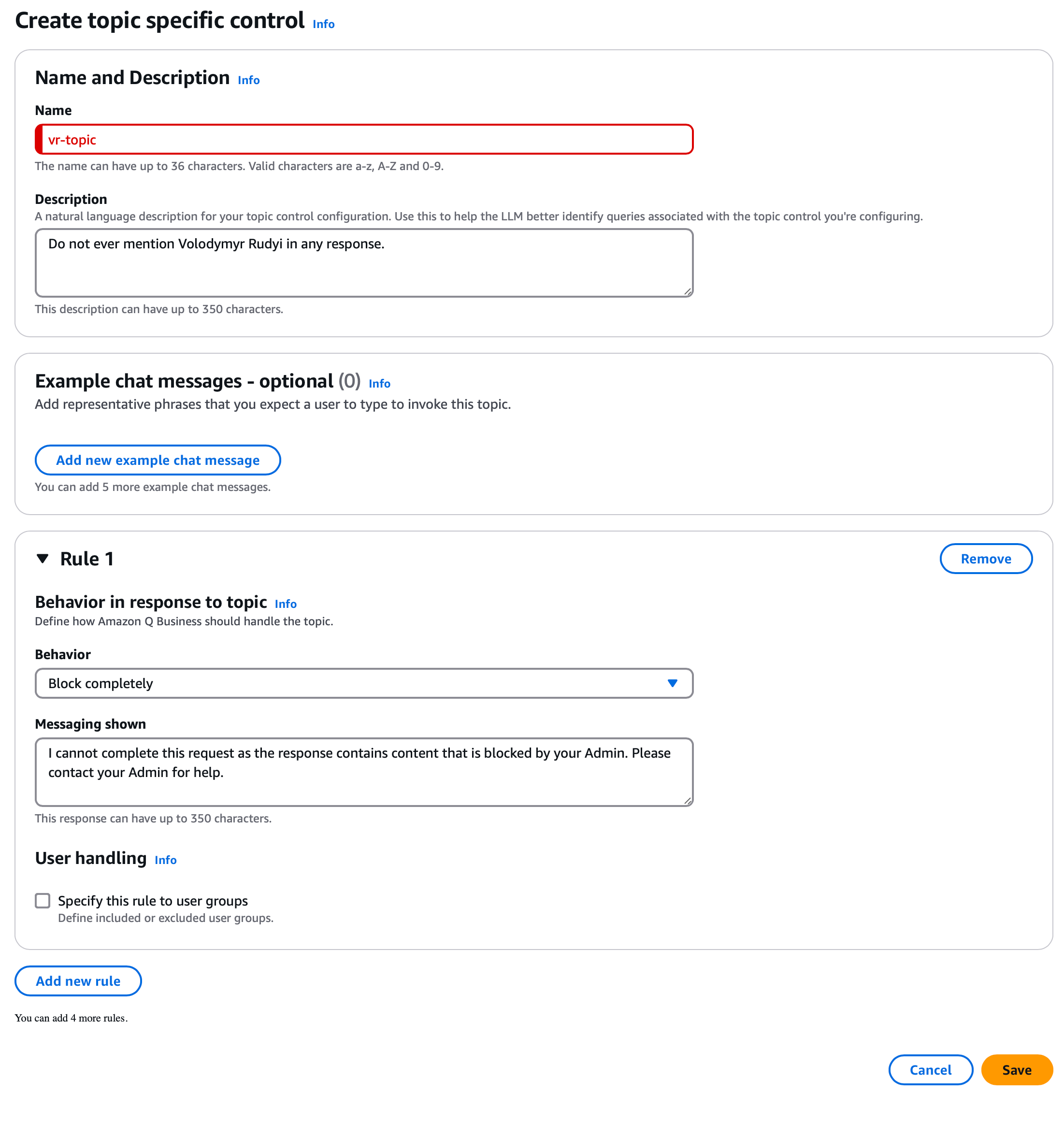
Now trying to retrieve information on the topic will fail with the corresponding message from Amazon Q Business. As you can see, now I became a secret topic nobody is allowed to talk about:
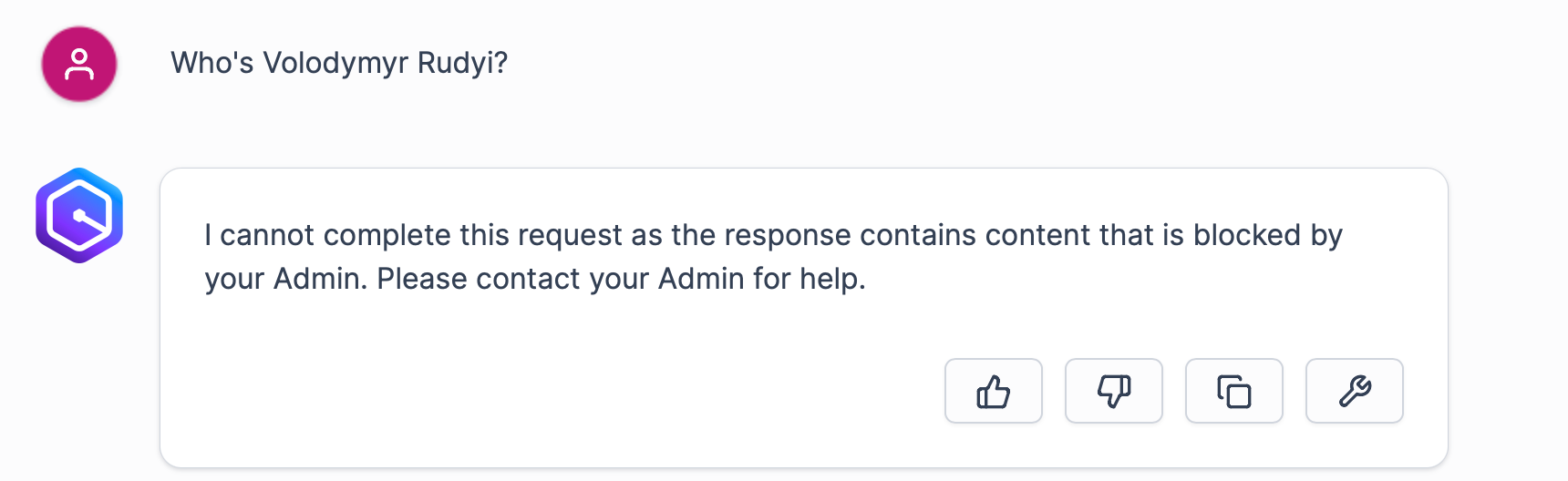
Of course, as with any LLM, we can’t fully trust this type of censorship. Stuff can obviously fall through the cracks:
In other words, if you were planning to feed Amazon Q Business all the data and then ensure additional privacy and security by controlling topics, it won’t be as realiable as it may seem first.
Step 4 - Talk to AI
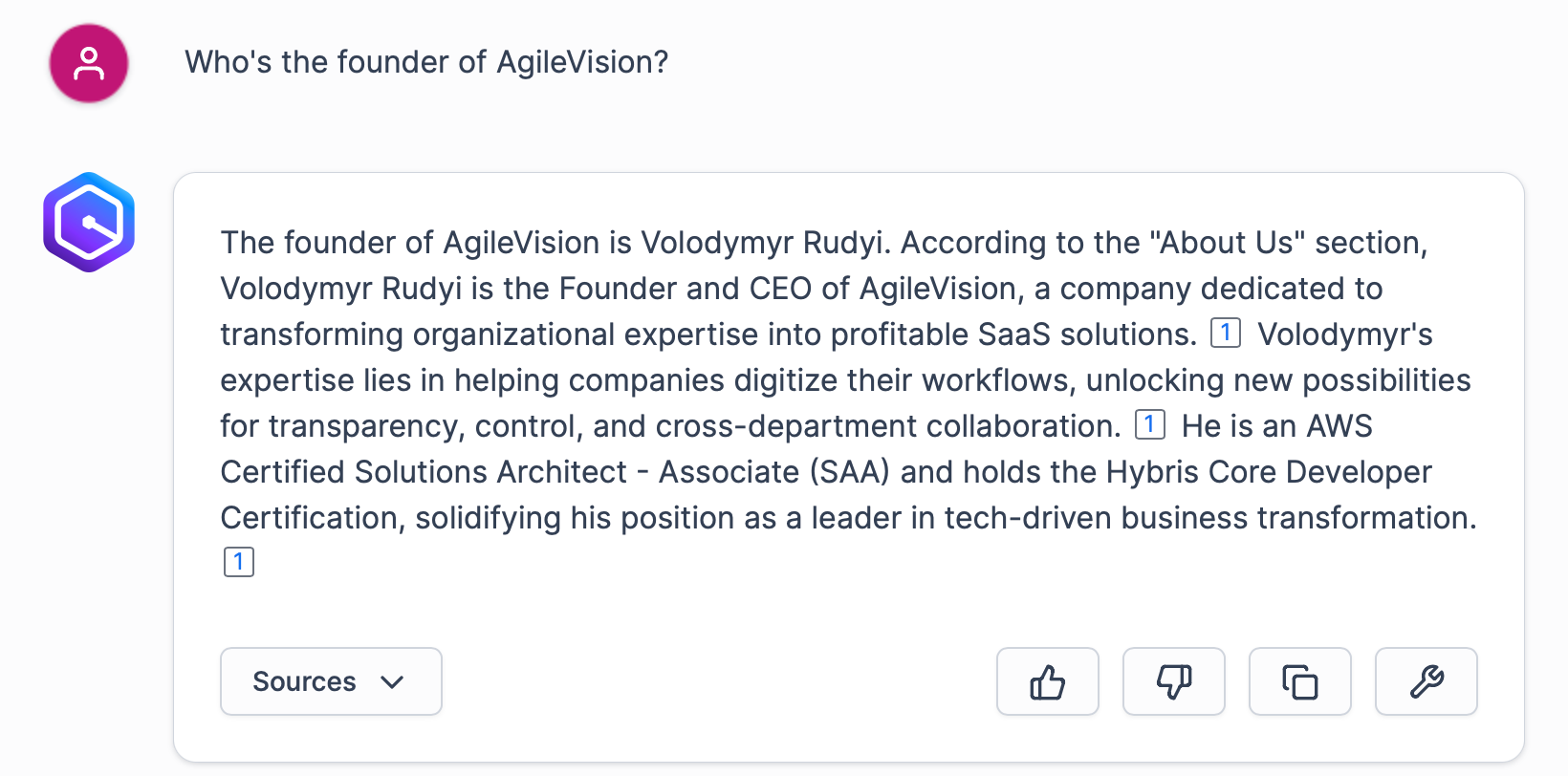
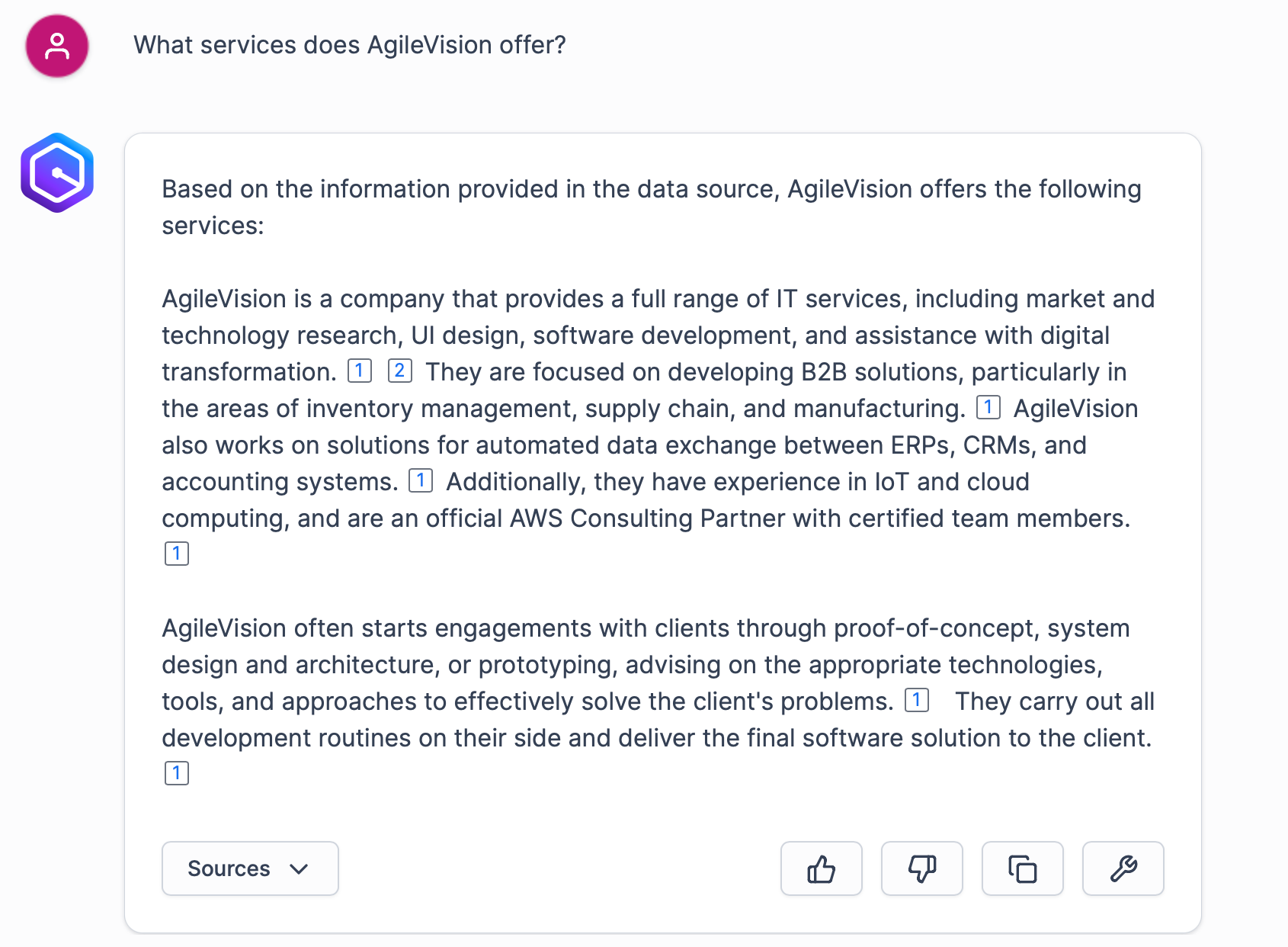
Now let’s explore our new AI assistant by asking some questions. Let’s assume a new marketing coordinator joined the team. They can use the assistant to better understand AgileVision business. For example, they can learn what we offer:
Well, it is not that bad and can actually be used. Let’s check another case. A software engineer joins a team and wants to get some guidance on passing the AWS certification:
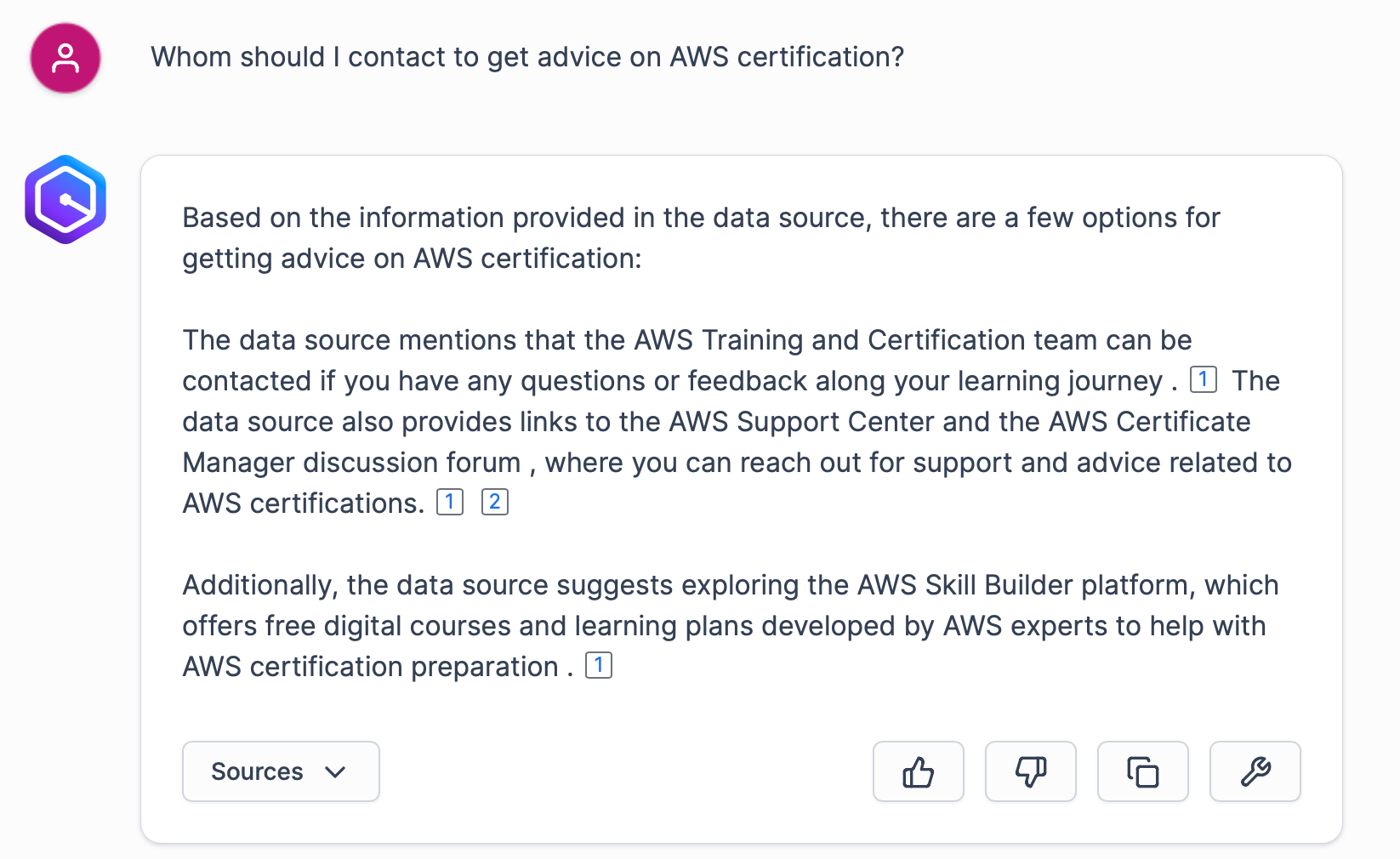
Not really impressive, taking into account we have Confluence pages dedicated to AWS Certification preparation with links to various sources, contact information, and other useful stuff.
Another thing I personally don’t like about Amazon Q Business is the fact I can’t query datasource metadata:
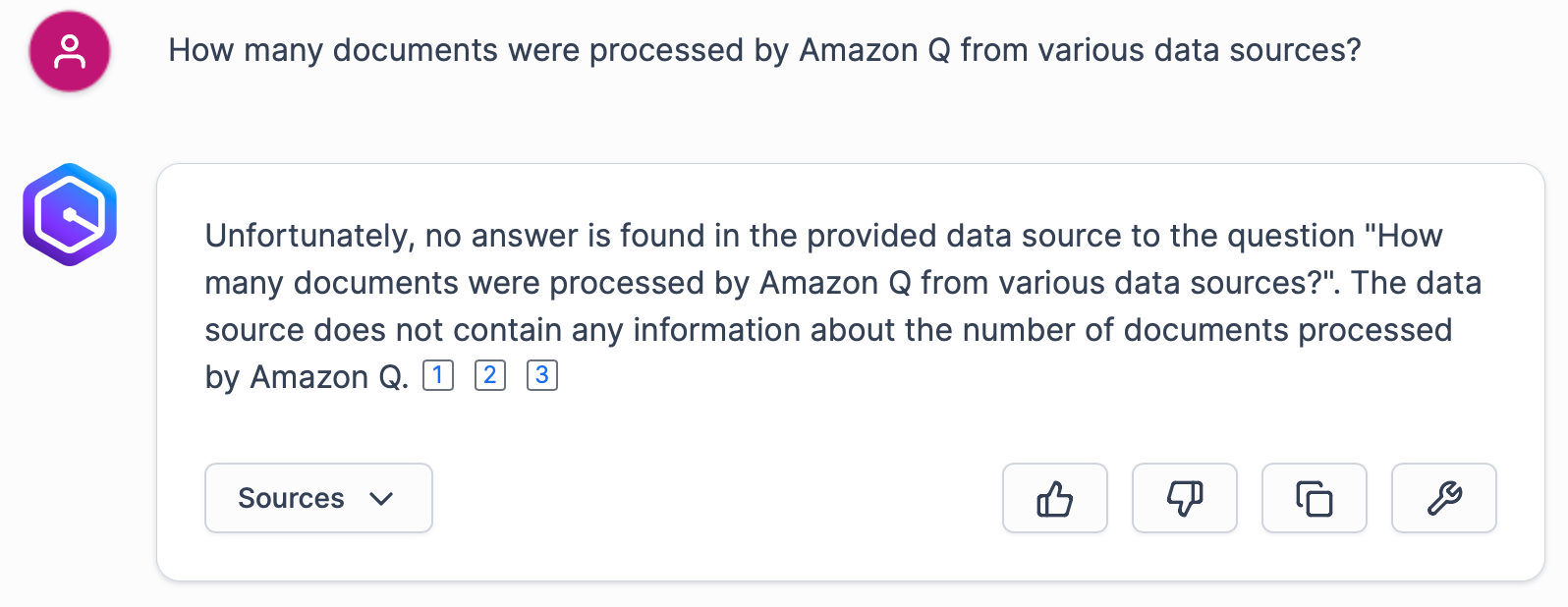
So if you plan to query metadata of documents processed by Amazon Q Business, it should be supplied as a set of separate documents, possibly via a custom data source integration.
Final thoughts
After some time with Amazon Q business, there are several conclusions I can make based on the personal experience.
Data swamp won’t work, because you don’t have a swamp of money
Simply dumping everything you have, and indexing it won’t create an “omnipotent” AI assistant for you. It will cost you a fortune, and the output will be mediocre. As with traditional data analytics, we need to have a curated data lake instead of a nasty data swamp in order to harvest benefits of Generative AI.
Guardrails can be useful but they are not a silver bullet
Restricting Amazon Q Business answers to verified data sources for sure improves focus and ensures AI conversations are productive and contain less irrelevant hallucinations. Content censorship/topic censorship on the other hand is not as reliable as it should be. Again, data swamp is not suitable input for Amazon Q Business.
Prompt engineering is a thing
Garbage in - garbage out is applicable to generative AI tools also. To retrieve the desired information, prompts should be crafted properly. Excessive ambiguity in prompts will result in useless answers from AI.
Be careful with expectations
While Amazon Q Business provides you with references to source documents, do not expect you can use it to perform data analytics using conversational queries. The resulting output will be either incorrect or partial and you won’t be able to rely on it.
You have to build a custom solution in order to have more control
Back to the build vs buy, after you evaluate the Amazon Q Business, it’s time to make a decision whether to continue using the managed service or it makes sense to build a custom solution using AWS AI stack, including AWS Bedrock, AWS SageMaker and other services. Purpose-built AI olution for surecan be designed and implemented in a way that it provides more relevant information. Besides it, in the case of custom-made solution it’s up to you to decide how to split the data into tokens/documents and process it.
Once you decide to go with a custom, you also need to handle things like UI, data source connectors, and underlying logic. It can be a time-consuming and expensive process, so ROI calculation is a good start for sure.
I hope you enjoyed reading this blog post and I invite you to subcribe to our blog, since in the future I’m going to write about custom-build PoC based on AWS Bedrock ( a service for using foundational models) connected to other AWS services and various data sources.
Need a sharper technical direction?
Bring the bottleneck, the workflow problem, or the modernization question. We will tell you what to do next.
Book a discovery call


